Zwalmy wszystko na Cloudflare i problem z głowy.
0
1
Potwierdzam, czasami powiadomienia/wiadomości przymulają do paru sekund
1
Dobra, przyłączam się do skarg na działanie serwisu:
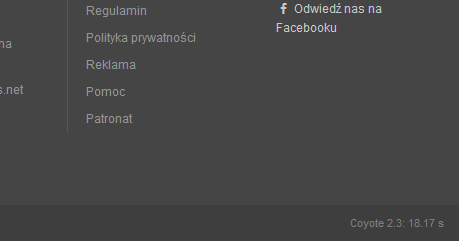
W sumie to już wcześniej miałem okazję zauważyć spore problemy, ale nie czekałem aż strona się załaduje tylko wciskałem Esc aby przerwać ładowanie i od razu F5 (lub drugi raz LPM na link) aby ponownie załadować stronę. Bo z reguły jeśli strona nie przeładuje mi się w sekundę od kliknięcia to szybka sekwencja wymienionych klawiszy i mam stronę załadowaną.
No a teraz postanowiłem poczekać i sprawdzić czy problemem jest moje łącze czy serwer – okazuje się, że serwer za długo mieli. Coś faktyczne nie działa tak jak powinno. :/
1
Sprawdziłem logi Postgresa z powolnymi zapytaniami i rzeczywiście lądują tam czasem zapytania, tak banalne że nie ma tam nawet co optymalizować. Typu: select "created_at" from "guests" where "guests"."id" = '862ff259-3bf2-4a02-8276-bd273c32d0df' limit 1. Robię EXPLAIN ANALYZE i wychodzi:
Limit (cost=0.56..2.78 rows=1 width=8) (actual time=0.028..0.028 rows=1 loops=1)
-> Index Scan using guests_pkey on guests (cost=0.56..2.78 rows=1 width=8) (actual time=0.026..0.026 rows=1 loops=1)
Index Cond: (id = '862ff259-3bf2-4a02-8276-bd273c32d0df'::uuid)
Planning time: 0.142 ms
Execution time: 0.059 ms
Mimo wszystko takie zapytanie wykonuje się czasem +1 sek :( Robię jeszcze VACUUM na tabeli i zobaczymy czy coś pomoże.
1
Ale faktycznie query działa tak długo jak bezpośrednio wykonujesz je na bazie, czy Coyote widzi taki czas? Bo może problem jest komunikacyjny a nie z bazą?
0
@Shalom: przeglądam bezpośrednio logi postgresa, a nie coyote, więc to raczej nie kwestia mapowania wyników w coyote.
1
Problem nie został nadal rozwiązany. Coś mi się wydaje że to ma związek z blokowaniem tabel przez Postgresa, przez co niektóre procesy muszą czekać na swoją kolej i stąd opóźnienia. W logach widzę wiele prób wykonywania autovacuum na tabeli sessions która jest bardzo często modyfikowana. Tymczasowo wyłączyłem autovacuum na taj tabeli i będę obserwował co się dzieje.
1
Po kilku godzinach obserwacji w logach pojawiło się kilka zapytań które zamulają. Wszystkie to zapytania typu INSERT albo UPDATE. Pojawiło się też kilka zapytań COMMIT ;) Generalnie problem jest w zapisie danych do bazy.
0
Kilka dni minęło, więc tak dla zasady przypomnę
Coyote 2.3: 4.80 s
1
Niestety nie wiem co jest przyczyną :( Czy ktoś jest w stanie pomóc w temacie?
0
Adam Boduch napisał(a):
Niestety nie wiem co jest przyczyną :( Czy ktoś jest w stanie pomóc w temacie?
Testowales cos na produkcji? :(
0
Adam Boduch napisał(a):
Niestety nie wiem co jest przyczyną :( Czy ktoś jest w stanie pomóc w temacie?
Technicznie niestety nie pomogę :/ Ale proponuję tym użytkownikom, którzy doświadczą owego niemiłego spowolnienia aby tu raportowali:
- wersja przeglądarki
- na ilu kartach oglądano 4programmers.net
- skąd się łączyli (telefon, tablet, PC)
- godzina połączenia
- ustawienia cookies
w miarę możliwości i pamiętania:
- od jakiego czasu mają włączoną kartę/karty 4programmers.net w przeglądarce
- kolejność buszowania po serwisie
3
Nie, nie. Raczej chodziło o pomoc w związku z PostgreSQL. Wiem, że przyczyną jest tutaj baza danych (a konkretnie zapis do niej), wersja przeglądarki itp. nie mają tutaj nic wspólnego.
Dzisiaj powinno być nieco lepiej. W najbliższym czasie zrobimy upgrade postgresa oraz postaram się jeszcze coś podkręcić samą konfiguracją.
0
Chyba jest trochę lepiej, co?
0
Zależy, kiedy coś zmieniłeś. Jeśli przed chwilą/w nocy to póki co wydaje się ok. Jeśli wcześniej to nie jestem pewien. Wczoraj siedziałem chwilę koło północy i było tak sobie.
0
Czas generowania zmniejszyl sie do 200-300 ms
0
@Adam Boduch: niestety nie jest lepiej – dzisiejszej nocy kilka razy miałem czas ładowania strony wątku rzędu 8-9 sekund. Dzisiaj jeszcze lagów nie doświadczyłem, ale dopiero co odpaliłem komputer. Jak coś to dam znać.
0
Nie jest lepiej. Przed chwilą 7-8 sekund mi się rozwijał dzwoneczek, a potem 6 czekałem na załadowanie się strony. Sam czas jej generowania (podany w stopce) był w okolicy 500ms, czyli (względnie) OK, ale całość czekania od kliknięcia do pojawienia się to właśnie wspomniane 6 sekund. Zresztą dzieje się to znacznie częściej. Tak tylko napisałem, żeby zepsuć Ci weekend ;)
0
Mi sie nawet generuje 9s czasem
0
Proste zapytanie update "users" set "visited_at" = now() where "id" = 1 potrafiło wykonywać się 300 - 600 ms (tabela niecałe 100k rekordów). Po wykonaniu VACUUM wartość spadła do 30 ms. Chyba tutaj jest trop. Będę musiał wykonać VACUUM FULL na niektórych tabelach oraz zmienić ustawienia autovacuum. Ponieważ ta operacja blokuje tabelę do zapisu, będę musiał to zrobić w nocy.
EDIT: Chociaż i tak u mnie na laptopie przy takich samych danych takie zapytanie wykonuje się z 13 ms :(
0
Czy grzebałeś coś przed chwilą?

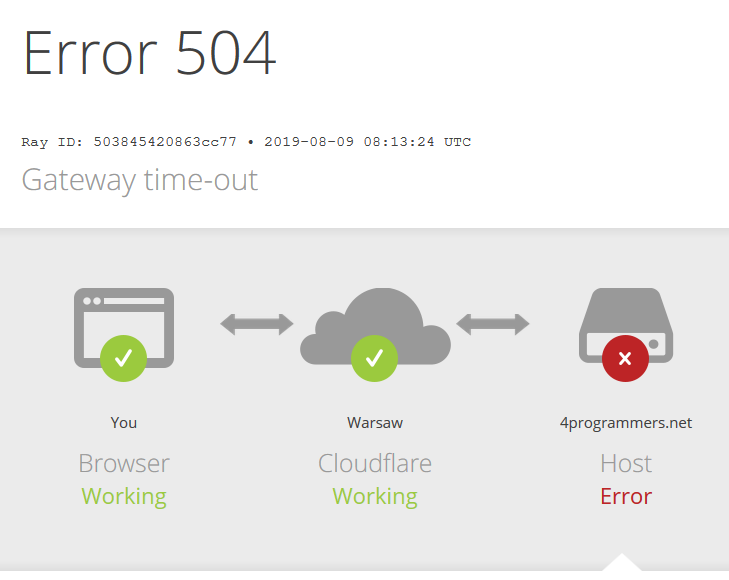
2
Ja nic nie mówię, ale:

0
VACUUM wykonany. Przy okazji zrobiony został upgrade do PHP 7.3. Powinno działać lepiej.
0
@cerrato: odpowiadam na Twój komentarz do mojego postu w sprawie wolnego przesyłu strony (nie jej generowania). Jeżeli używasz Chrome, to przejdź do narzędzi deweloperskich (na FF oczywiście też są), następnie do zakładki Network. Poniższy screen przedstawia akurat analizę podstrony Praca. Większość zasobów (CSS czy JS) jest w cache więc ściągamy tak naprawdę treść strony.
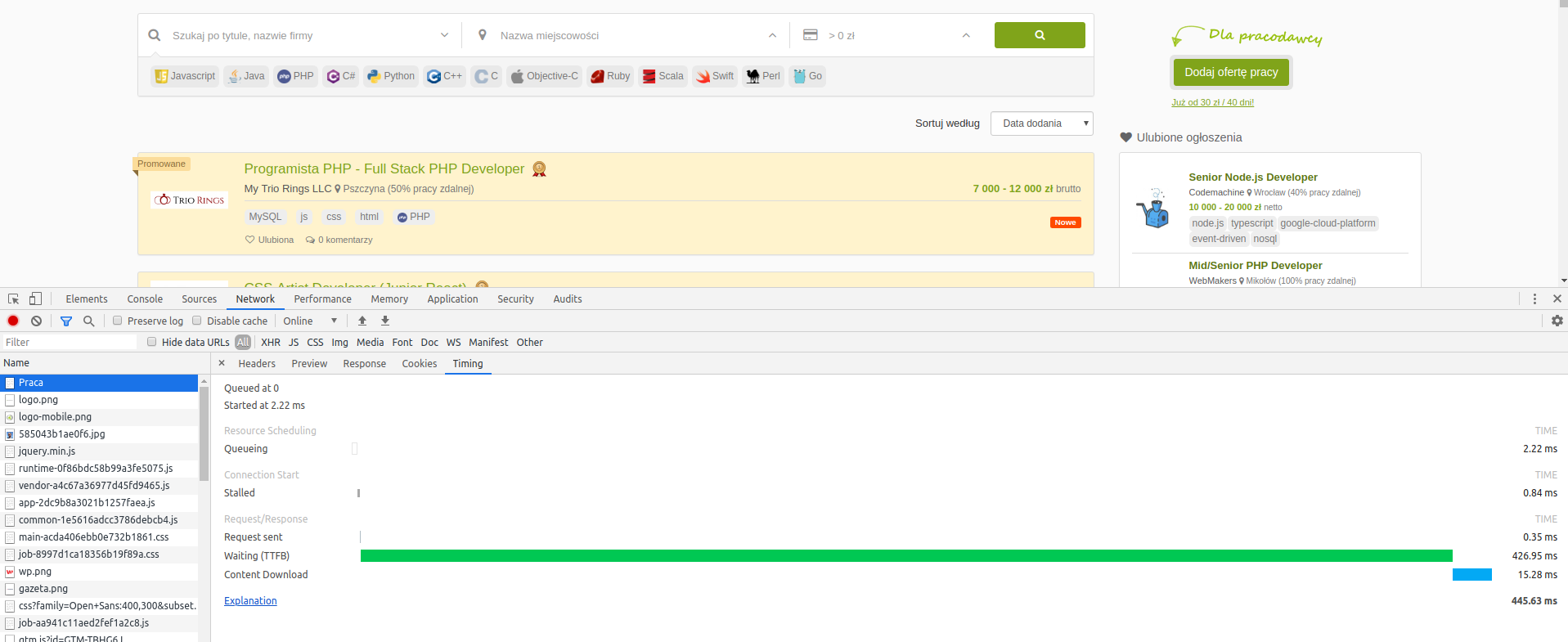
Zielony wykres (TFFB) prezentuje tak naprawdę czas generowania strony po stronie serwera. Jak można zauważyć, jest on większy niż czas podawany w stopce strony. Wszystko dlatego, że w stopce prezentowany jest czas generowania strony przez samego Coyote. Do tego dochodzi tutaj żądanie do nginx, następnie do php-fpm oraz ewentualne lagi.
Na niebieskim wykresie przedstawiony jest czas ściągania danego zasobu. Oczywiście używamy HTTP2.
Strona główna forum:

Jak to u Ciebie wygląda?
0
Z tym wątkiem jest trochę jak z Krzysztofem Krawczykiem - jest nieśmiertelny i co pewien czas powraca do głównego obiegu ;)
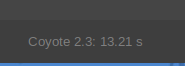
Ostatnio znowu widzę (okresowe) przymulenia, obrazek (fakt, że ogromny ;) ) wklejał się z 15 sekund.
1
Zamuły ostatnio zdarzają się podczas wysyłania posta. Np. przed chwilą czas generowania strony wyniósł prawie siedem sekund, pomimo tego, że wysłałem post z jednym zdaniem (bez załączników i innych cukierków).
0
U mnie działa :D
2
Pracuje nad tym aby to usprawnić. Problemem są zapytania INSERT/UPDATE na tabeli która ma sporo indeksów. Przeniosę te operacje do kolejki zadań w tle tak więc powinno to przyspieszyć czas generowania stron.
1
Skorzystałem z narzędzia pg_test_fsync aby przetestować prędkość zapisu na dysk. Najpierw wyniki z mojego kompa, a potem z serwera:
Compare file sync methods using one 8kB write:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync 1589.229 ops/sec 629 usecs/op
fdatasync 1608.691 ops/sec 622 usecs/op
fsync 1328.306 ops/sec 753 usecs/op
fsync_writethrough n/a
open_sync 1326.776 ops/sec 754 usecs/op
Compare file sync methods using two 8kB writes:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync 811.277 ops/sec 1233 usecs/op
fdatasync 1394.690 ops/sec 717 usecs/op
fsync 1018.701 ops/sec 982 usecs/op
fsync_writethrough n/a
open_sync 606.714 ops/sec 1648 usecs/op
Compare open_sync with different write sizes:
(This is designed to compare the cost of writing 16kB in different write
open_sync sizes.)
1 * 16kB open_sync write 1197.724 ops/sec 835 usecs/op
2 * 8kB open_sync writes 674.533 ops/sec 1483 usecs/op
4 * 4kB open_sync writes 352.828 ops/sec 2834 usecs/op
8 * 2kB open_sync writes 175.481 ops/sec 5699 usecs/op
16 * 1kB open_sync writes 85.859 ops/sec 11647 usecs/op
Test if fsync on non-write file descriptor is honored:
(If the times are similar, fsync() can sync data written on a different
descriptor.)
write, fsync, close 1310.072 ops/sec 763 usecs/op
write, close, fsync 1328.503 ops/sec 753 usecs/op
Non-sync'ed 8kB writes:
write 164801.870 ops/sec 6 usecs/op
Serwer:
Compare file sync methods using one 8kB write:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync n/a*
fdatasync 151.845 ops/sec 6586 usecs/op
fsync 219.179 ops/sec 4562 usecs/op
fsync_writethrough n/a
open_sync n/a*
* This file system and its mount options do not support direct
I/O, e.g. ext4 in journaled mode.
Compare file sync methods using two 8kB writes:
(in wal_sync_method preference order, except fdatasync is Linux's default)
open_datasync n/a*
fdatasync 250.101 ops/sec 3998 usecs/op
fsync 262.281 ops/sec 3813 usecs/op
fsync_writethrough n/a
open_sync n/a*
* This file system and its mount options do not support direct
I/O, e.g. ext4 in journaled mode.
Compare open_sync with different write sizes:
(This is designed to compare the cost of writing 16kB in different write
open_sync sizes.)
1 * 16kB open_sync write n/a*
2 * 8kB open_sync writes n/a*
4 * 4kB open_sync writes n/a*
8 * 2kB open_sync writes n/a*
16 * 1kB open_sync writes n/a*
Test if fsync on non-write file descriptor is honored:
(If the times are similar, fsync() can sync data written on a different
descriptor.)
write, fsync, close 282.906 ops/sec 3535 usecs/op
write, close, fsync 120.222 ops/sec 8318 usecs/op
Non-sync'ed 8kB writes:
write 136888.817 ops/sec 7 usecs/op
Coś tu jest nie tak, coś słabo serwer wypada. @msm rzucisz okiem?
EDIT:
sprawdzona prędkość zapisu. U mnie lokalnie 1.6 GB/S, na serwerze 1.0 GB/S :(
Polecenie: sudo dd if=/dev/zero of=/tmp/output bs=8k count=10k; rm -f /tmp/output
0
Z kolei gdy użyje dd to serwer ma naprawde dobre wyniki:
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.509682 s, 2.1 GB/s
U mnie na kompie:
dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync
1+0 records in
1+0 records out
1073741824 bytes (1,1 GB, 1,0 GiB) copied, 4,4935 s, 239 MB/s
Nie wiem już o co chodzi ...
Chyba będzie potrzebna nowa maszyna na bazę.